Servicenavigation
Suche
Numerische Wettermodelle bilden die Grundlage für alle unsere Vorhersagen. Diese komplexen Computerprogramme werden ständig verbessert und damit auch unsere Vorhersagen. Wettermodelle sind äusserst nützlich, aber sie sind nicht perfekt.
Selbst unsere hochauflösenden Modelle können das komplexe Terrain der Alpen nicht vollständig darstellen. Stattdessen muss eine vereinfachte Darstellung der Topographie verwendet werden. Dies hat zur Folge, dass kleinräumige Prozesse, die für unser Wetter relevant sind, vom Modell nicht vollständig aufgelöst werden können. Dies führt zu systematischen Fehlern.
Darüber hinaus liefern Wettermodelle eine Fülle von Informationen über das zukünftige Wetter, einschliesslich mehrerer plausibler Ergebnisse, um die Unsicherheit der Vorhersage abzuschätzen. Um diese Informationsflut zu bewältigen, müssen Vorhersagen aus verschiedenen Wettermodellen kombiniert und harmonisiert werden.
Um verschiedene Wettermodelle automatisch zu einer einzigen, zuverlässigen und qualitativ hochwertigen Konsensprognose zu kombinieren, verwenden wir statistische und maschinelle Lernmethoden. Dies wird als statistisches Postprocessing bezeichnet.
Wie werden unsere Prognosen nachbearbeitet?
Bei der Nachbearbeitung werden Vorhersagen von Wettermodellen korrigiert und kombiniert, indem frühere Vorhersagen mit Beobachtungen verglichen werden. Für die verschiedenen meteorologischen Parameter wie Wind, Bewölkung und Niederschlag setzen wir verschiedene statistische und maschinelle Lernmodelle ein. Diese unterscheiden sich in der Auswahl der Eingaben aus den Wettermodellen und in den Verteilungsannahmen der Vorhersagewerte. Die Modelle unterscheiden sich auch in ihrer Komplexität, die von linearen Methoden (den gut etablierten Ensemble-Modell-Ausgangsstatistiken) bis hin zu neuartigen Deep-Learning-Ansätzen mit neuronalen Netzen (derzeit für die Nachbearbeitung des Windes verwendet) reicht.

Allen unseren Nachbearbeitungen ist gemeinsam, dass wir nicht nur versuchen, systematische Fehler zu minimieren, sondern auch die Variabilität der plausiblen Prognoseergebnisse so anzupassen, dass sie die tatsächliche Unsicherheit der Prognose besser widerspiegeln, wie in Abbildung 2 dargestellt. Dies führt zu probabilistischen Prognosen, die zuverlässiger und damit nützlicher sind.
Schließlich werden bei der Nachbearbeitung auch Informationen aus verschiedenen Wettermodellen kombiniert. Dies geschieht auf automatisierte und objektive Weise, so dass sich der relative Beitrag der einzelnen Wettermodelle je nach Vorhersagezeit (wie weit in die Zukunft wir prognostizieren), Ort, Jahreszeit und vielen anderen Aspekten ändert. Im Allgemeinen wird jedoch unseren hochauflösenden Modellen zu Beginn der Vorhersage mehr Gewicht beigemessen, während das globale, grob aufgelöste Modell der einzige Input ist, der für die Vorhersagen mit mehr als 5 Tagen Vorlauf verwendet wird.
Dieser Multi-Modell-Ansatz führt zu nachbearbeiteten Vorhersagen, die weniger sprunghaft sind. Das heißt, dass radikale Änderungen der Vorhersagen eines einzelnen Wettermodells von einer Vorhersageinitialisierung zur nächsten die nachbearbeiteten Vorhersagen weniger beeinflussen. Außerdem variieren die systematischen Fehler im Laufe der Zeit gleichmäßiger im Vergleich zum alten System, bei dem die Vorhersagefehler stark vom verwendeten Einzelwettermodell abhingen (siehe Abbildung 2).
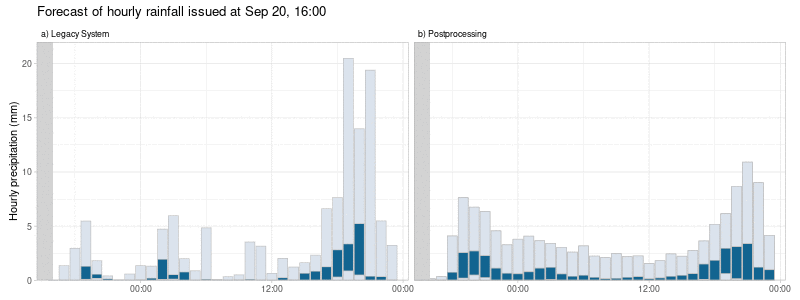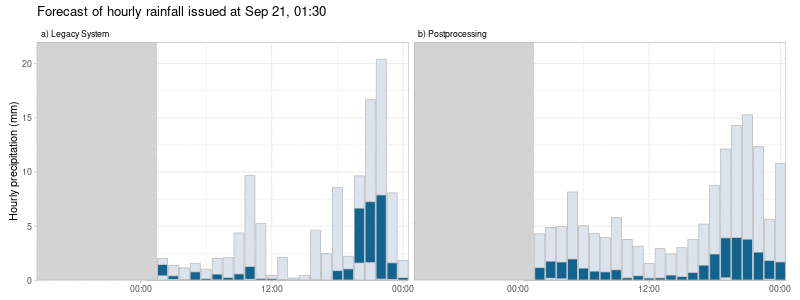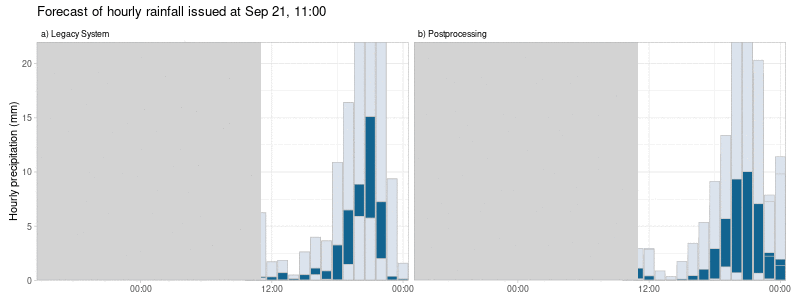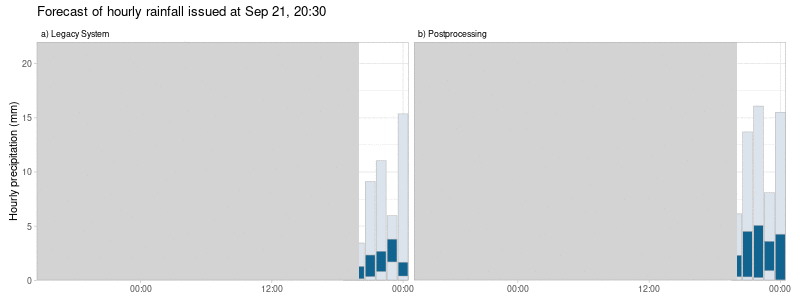
Wie unterscheiden sich die nachbearbeiteten Vorhersagen von den Wettermodellen?
In erster Linie werden beim Postprocessing statistische Methoden verwendet, um die Vorhersagen der Wettermodelle zu korrigieren. Die Vorhersagen unterscheiden sich also nicht grundlegend von den Vorhersagen der Wettermodelle, die als Input für das Postprocessing verwendet werden. Insbesondere erfindet das Postprocessing keine neuen Vorhersagen und kann nicht verhindern, dass die Vorhersagen im Einzelfall erheblich abweichen. Was das Postprocessing jedoch bewirkt, ist eine Verringerung des systematischen Fehlers im Durchschnitt.
Ein Teil dieser Verringerung des Vorhersagefehlers lässt sich auf die höhere scheinbare Auflösung der nachbearbeiteten Vorhersagen zurückführen. Durch die Verwendung zusätzlicher Informationen, wie z. B. hochauflösender Höhendaten, können die Vorhersagen um die Höhe, die Exposition und andere Effekte, die sich auf die lokalen Bedingungen auswirken, bereinigt werden. Dadurch werden die nachbearbeiteten Vorhersagen lokalisierter (Abbildung 3). Es muss ein Gleichgewicht gefunden werden zwischen der Erstellung spezifischer Vorhersagen, die an einem bestimmten Punkt optimal sind, aber nur für das unmittelbare Gebiet repräsentativ sind, und Vorhersagen, die für größere Gebiete repräsentativ sind, die weniger repräsentativ für lokale Besonderheiten sind, aber leichter zu interpretieren.

Nachbearbeitete Vorhersagen sind im Allgemeinen unsicherer als die Vorhersagen der einzelnen Wettermodelle (siehe Abbildung 2). Die Nachbearbeitung berücksichtigt mehrere zusätzliche Unsicherheitsquellen, die in den Ensemble-Vorhersagen der Wettermodelle nicht berücksichtigt werden. Die Vorhersagen eines einzelnen Ensemblesystems sind einander sehr viel ähnlicher als die eines anderen Wettermodells. Durch die Kombination mehrerer Modelle im Postprocessing wird diese zusätzliche Quelle der Unsicherheit in den nachbearbeiteten Vorhersagen berücksichtigt. Das Postprocessing berücksichtigt auch zusätzliche Variabilitätsquellen in den Beobachtungen, die in den Wettermodellen nicht enthalten sind. Diese zusätzliche Variabilität ist oft auf lokale Effekte zurückzuführen und kann die Unsicherheit der Vorhersage weiter erhöhen.
Gewitter sind für einen Großteil unserer Sommerniederschläge verantwortlich. Die Vorhersage von Gewittern ist jedoch schwierig, da der Zeitpunkt und der Ort dieser Gewitter oft nicht mehrere Stunden im Voraus bestimmt werden können. Würden wir eine einzige beste Vorhersage erstellen, würde diese in diesen von Natur aus unvorhersehbaren Situationen oft das Ziel verfehlen. Stattdessen erstellen unsere Vorhersagemodelle und nachbearbeiteten Prognosen viele plausible Realisierungen, um die Unsicherheit der Vorhersage zu quantifizieren. Dies wird als Ensemble oder probabilistische Vorhersage bezeichnet.
In unserem Beispiel können wir die vielen Realisierungen nutzen, um die Niederschlagswahrscheinlichkeit zu schätzen. An einem typischen Sommertag zeigt die Mehrheit der Vorhersage-Realisierungen einige Stunden nach der Vorhersage keinen Niederschlag für den Nachmittag, aber einzelne Ensemble-Mitglieder - wenn ein Gewitter über den interessierenden Ort zieht - können starke Niederschläge vorhersagen. Daher ist es wichtig, sich nicht nur auf das wahrscheinlichste Ergebnis (kein Regen) zu konzentrieren, sondern auch auf die weniger wahrscheinlichen Ergebnisse, die große Auswirkungen haben (Gewitter mit Starkregen). Dies verdeutlicht den Nutzen der probabilistischen Vorhersage. Andererseits müssen wir lernen, mit unsicheren Prognosen umzugehen, um von den zusätzlichen Informationen zu profitieren.
Trotz ihrer Ungewissheit können wir die Qualität probabilistischer Vorhersagen in ähnlicher Weise bewerten wie eine einzelne (deterministische) Vorhersage. Nachdem wir das tatsächliche Wetter beobachtet haben, berechnen wir den Prognosefehler. Dieser Fehler hängt davon ab, wie weit die Vorhersage daneben lag, aber auch davon, wie sicher die Vorhersage ist. Eine Vorhersage mit geringer Unsicherheit, die das Ziel erreicht, hat einen geringeren Vorhersagefehler als eine Vorhersage mit hoher Unsicherheit, die das Ziel erreicht, oder eine Vorhersage mit geringer Unsicherheit, die das Ziel verfehlt.
Wir können auch beurteilen, ob die Vorhersageunsicherheit oder die Spanne der probabilistischen Vorhersagen allgemein angemessen ist. Wir können zum Beispiel überprüfen, ob es in 60 % der Zeit, für die wir eine 60 %ige Regenwahrscheinlichkeit vorausgesagt haben, tatsächlich geregnet hat. Wir stellen fest, dass die Unsicherheit der nachbearbeiteten Prognosen im Durchschnitt angemessen ist. Vorhersagen von einzelnen Wettermodellen sind dagegen oft zu sicher, d. h. im obigen Beispiel regnet es vielleicht nur in 40 % der Fälle, für die die Vorhersagewahrscheinlichkeit des Wettermodells 60 % betrug.